本文共 13218 字,大约阅读时间需要 44 分钟。
hive分享总结
1. 数据家谱:
- 关系型数据库
- 非关系型数据库
- 数据仓库

1.1.Hive 是什么?
Hive 是一个类SQL 能够操作hdfs 数据的数据仓库基础架构
Hive 是一个SQL 的解析引擎,能够将HSQL翻译MR在hadoop 中执行。 hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。总结:
Hive 是一个类SQL 能够操作hdfs 数据的数据仓库基础架构 Hive 是一个SQL 的解析引擎,能够将HSQL翻译MR在hadoop 中执行。1.2.数据仓库
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制,简而言之,数据仓库是用来做查询分析的数据库,基本不用来做插入,修改,删除;
1.3.Hive与传统数据库的区别
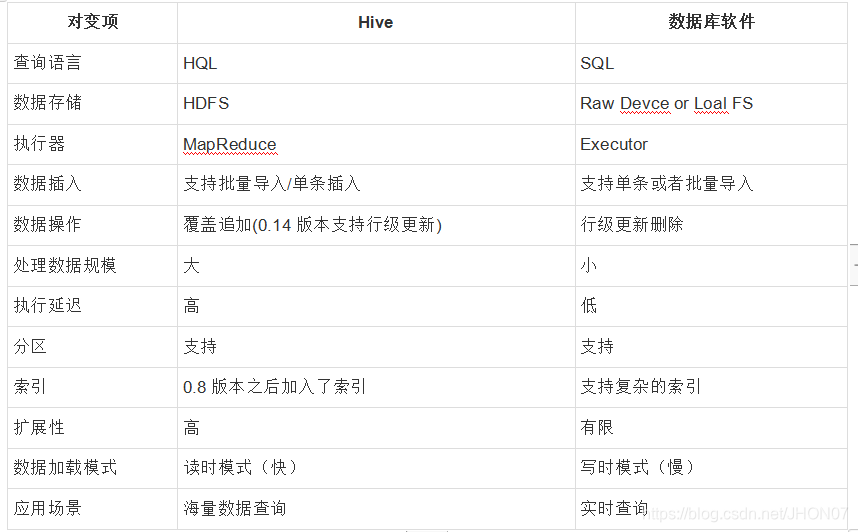
1.4.Hive的优缺点
优点:操作接口采用了类SQL语法,提供快速开发的能力,避免了去写MapReduce;Hive还支持用户自定义函数,用户可以根据自己的需求实现自己的函数。
缺点:Hive查询延迟很严重。1.5.Hive使用场景
- 数据的离线处理;比如:日志分析,海量结构化数据离线分析…
- Hive的执行延迟比较高,因此hive常用于数据分析的,对实时性要求不高的场合;
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
1.6.Hdfs 运行机制
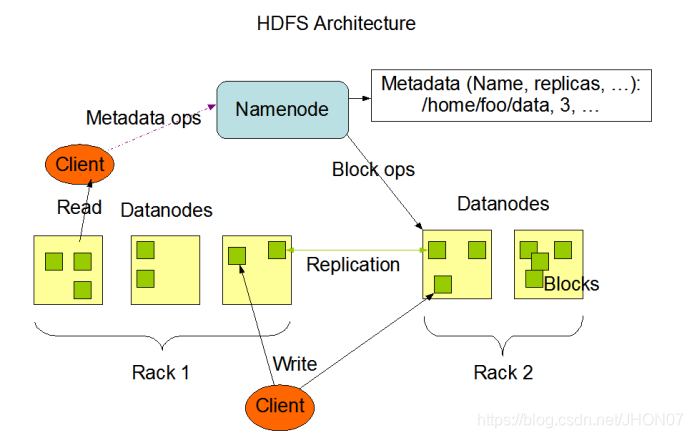
1.7.Mapreduce 运行机制
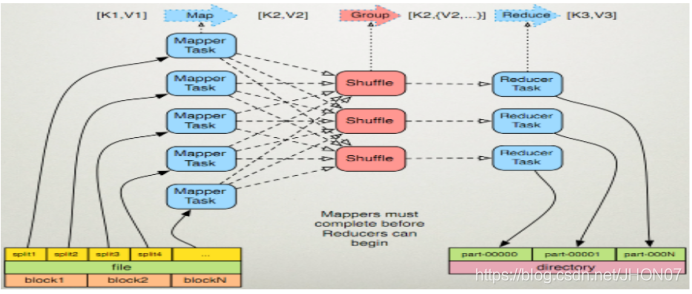
1.8.SQL转化成MapReduce过程
- Hive是如何将SQL转化为MapReduce任务的,整个编译过程分为六个阶段:
- 1-Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree;
- 2-遍历AST Tree,抽象出查询的基本组成单元QueryBlock;
- 3-遍历QueryBlock,翻译为执行操作树OperatorTree;
- 4-逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量;
- 5-遍历OperatorTree,翻译为MapReduce任务;
- 6-物理层优化器进行MapReduce任务的变换,生成最终的执行计划。


1.9.Hive 架构:
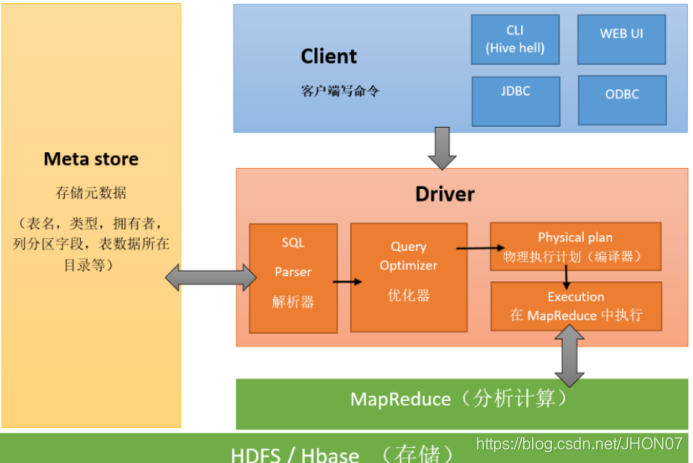
2.Hive交互方式
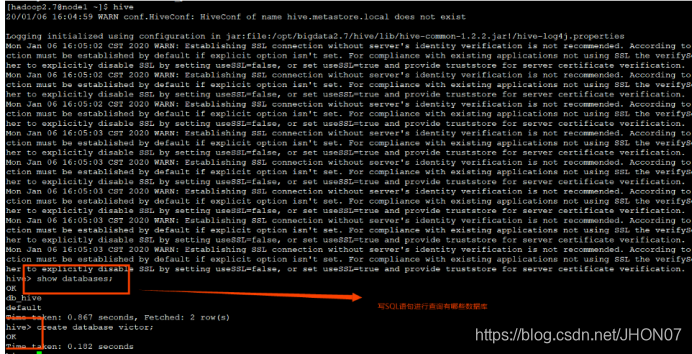
2.1.Hive交互shell
./hive 命令方式
bin/hive
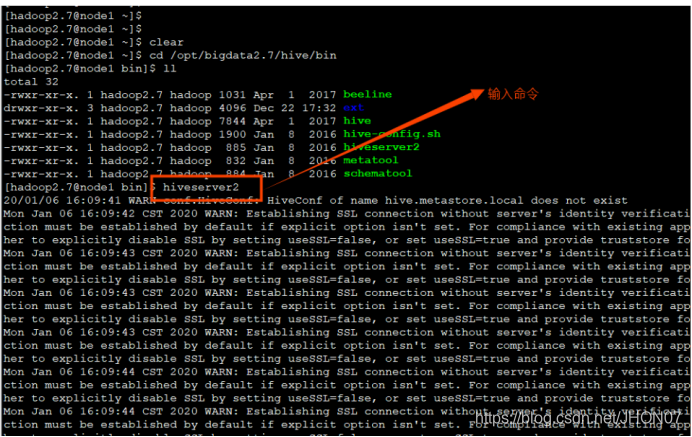
2.2.JDBC交互
输入hiveserver2相当于开启了一个服务端,查看hivesever2的转态
输入netstat –nlp命令查看:
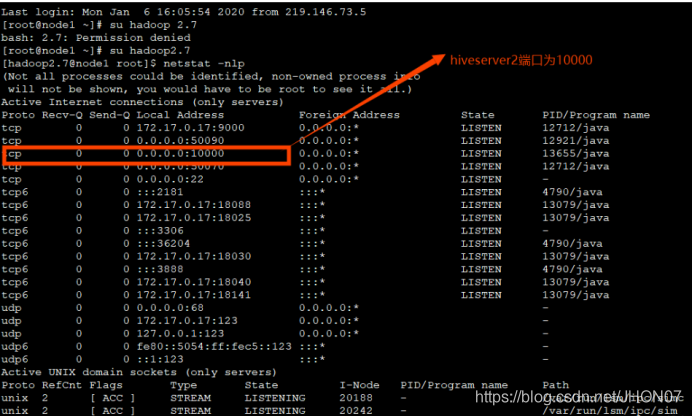
运行hiveserver2相当于开启了一个服务端,端口号10000,需要开启一个客户端进行通信,所以打开另一个窗口,输入命令beeline.
Example : : beeline -u jdbc:hive2://192.168.122.1:10000/default -n hive-p hive@12 beeline -u jdbc:hive2://192.168.122.1:10000/default -n hive-p hive@12 -e ‘select * from dual;’
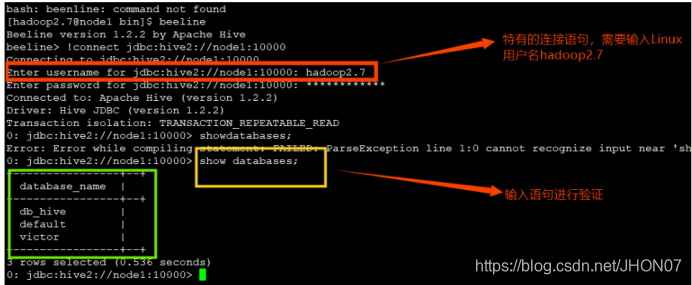
2.3.第三种交互方式:
使用sql语句或者sql脚本进行交互
vim hive.sql create database if not exists mytest; use mytest; create table stu(id int,name string); hive -f /export/servers/hive.sql
3.Hive 基础
3.1.hive 支持的基本类型
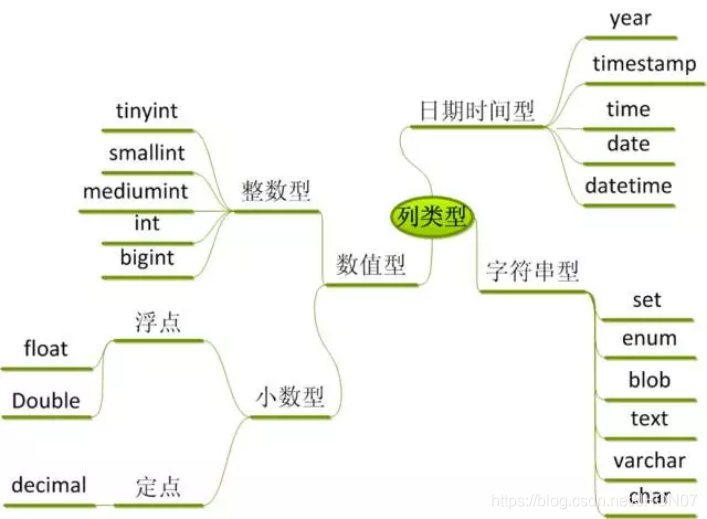
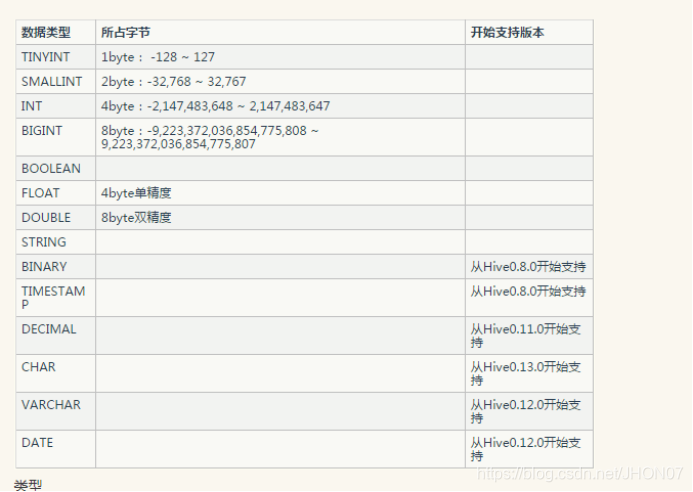
3.2.基本SQL语句
insert、delete、update、select
多表查询与代数运算 内连接 外链接 左连接 右链接 交叉链接 条件查询 Select where Select order by Select group by Select join 目前使用方式: 将sql 封装到 sh 例如:/home/hadoop/sh/bet_rr_indicator_1.0.sh
3.3.排序
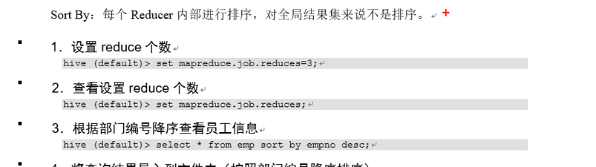
全局排序:
Order by 全局排序,只有一个reducer Sort by 每个reducer 内部配置 需要设置reducer 个数:
Distribute by

Cluster by 只能升序排序:

3.4.行转列

3.5.列转行

排序函数
Rank() 对应下图 rand_window_0 Dense_rank() 对应下图_ dense_rank_window_1 Row_number() 对应下图 row_number_window_2

3.6.hive 内连接外连接
多表查询与代数运算
内连接:
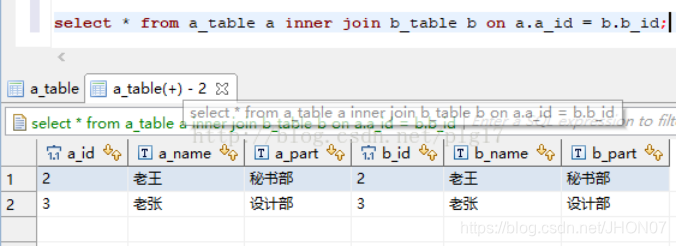
外链接
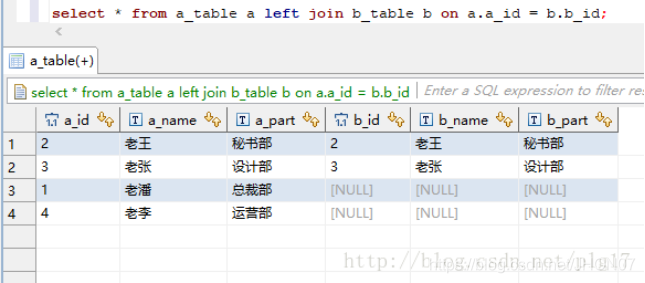
右连接:
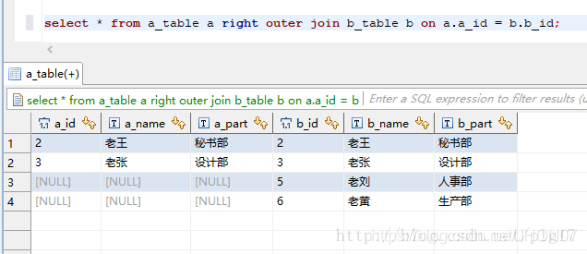
3.7.Hive 存储格式
自定义编译(练习)

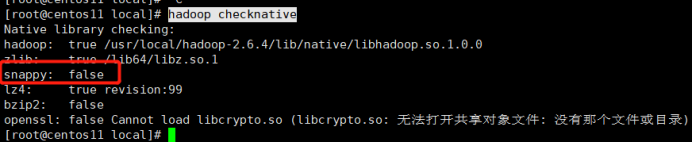
Hive 查看存储格式:
hadoop checknative Snappy 得添加snappy 的jar 重新编译hadoop.jar
Map 设置压缩方式:
验证: UI界面 任务的history–>configuration

Reduce 输出压缩的格式:
检查是否设置成功:从导入文件中查看文件的格式:


3.7.1.行存储和列存储
row layout 表示行存储
column layout 表示列存储
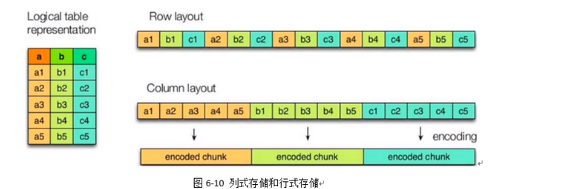

Textfile 和sequencefile的存储格式是基于行存储的 orc 和parquet 是基于列表存储的
3.7.2.textfile 格式:

3.7.3.Orc 格式
不是完成的列存储: 是将按照256M 进行切分 每个256 是一个stripe, stripe 是按照列方式存储,stripe 是按照256M 横向切分,因此不是完全列存储;

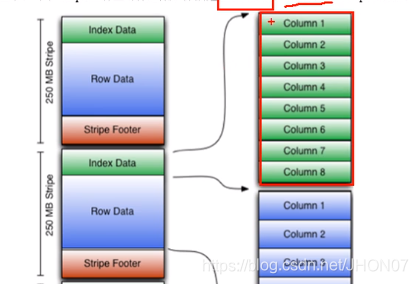
3.7.4.Parquet 存储格式
parquet 是一个二进制存储格式: (简单看)

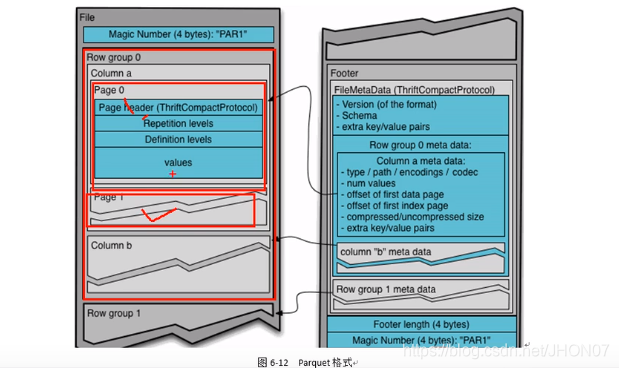
3.8.内部表/外部表
- 内部表 内部表数据由Hive自身管理,数据存储的位置是hive.metastore.warehouse.dir 删除内部表会直接删除元数据(metadata)及存储数据
- 外部表 外部表数据的存储位置由自己制定,可以在云端 删除外部表仅仅会删除元数据 表结构和数据都将被保存
CREATE EXTERNAL TABLE
test_table(id STRING, name STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’ LOCATION ‘/data/test/test_table’; – 导入数据到表中(文件会被移动到仓库目录/data/test/test_table) LOAD DATA INPATH ‘/test_tmp_data.txt’ INTO TABLE test_table;
3.9.hive元数据存储
Hive中metastore(元数据存储)的三种方式:
Hive将元数据存储在RDBMS中,有三种模式可以连接到数据库: a)内嵌Derby方式 b)Local方式 c)Remote方式
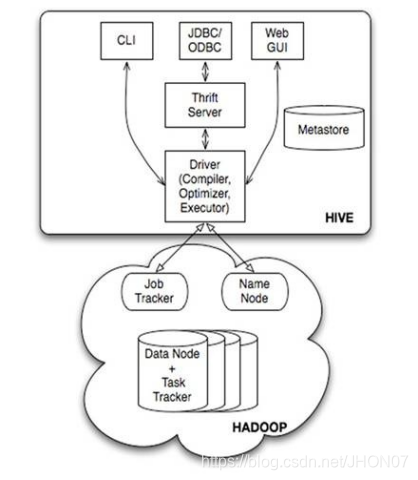
单用户本地模式:
1、元数据库内嵌模式:此模式连接到一个In-memory 的数据库Derby,一般用于Unit Test。
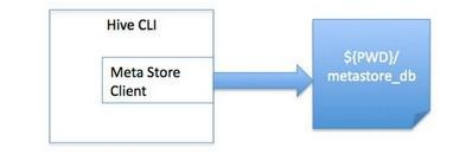
多用户模式:
2、元数据库mysql模式:通过网络连接到一个数据库中,是最经常使用到的模式。
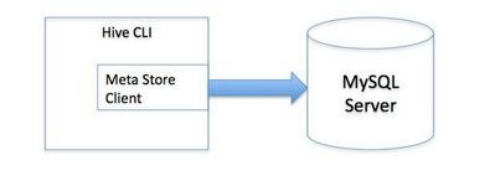
多用户远程模式
3、MetaStoreServe访问元数据库模式:用于非Java客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。
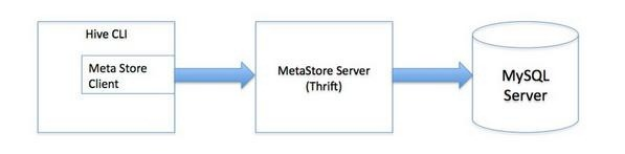
3.10.分区:
就是在系统上建立文件夹,把分类数据放在不同文件夹下面,加快查询速度
实战 CREATE TABLE logs(ts BIGINT, line string) partitioned BY (dt String, country string) ROW format delimited fields terminated BY ‘\t’;
load DATA LOCAL inpath ‘/Users/Ginger/Downloads/dirtory/doc/7/data/file1’ INTO
TABLE logs PARTITION (dt = ‘2001-01-01’, country = ‘GB’);
show partitions logs;
3.11.分桶:
桶是比分区更细粒度的划分:就是说分区的基础上还还可以进行分桶;hive采用对某一列进行分桶的组织;hive采用对列取hash值,然后再和桶值进行取余的方式决定这个列放到哪个桶中;
create table if not exists center( id int comment ‘’ , user_id int comment ‘’ , cts timestamp comment ‘’ , uts timestamp comment ‘’ ) comment ‘’ partitioned by (dt string) clustered by (id) sorted by(cts) into 10 buckets ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ stored as textfile ;
3.12 大数据应用架构

3.13 数据仓库架构
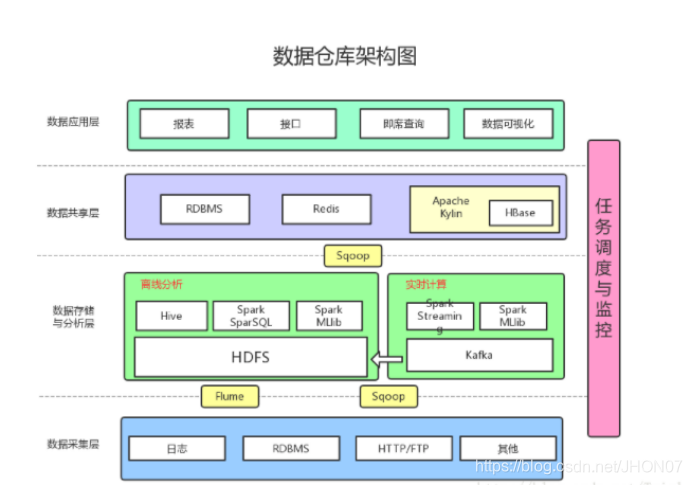
4.遇到的问题;
4.1.Hive sql 执行的顺序与mysql 对比:
Map阶段:
1.执行from加载,进行表的查找与加载 2.执行where过滤,进行条件过滤与筛选 3.执行select查询:进行输出项的筛选 4.执行group by分组:描述了分组后需要计算的函数 5.map端文件合并:map端本地溢出写文件的合并操作,每个map最终形成一个临时文件。 然后按列映射到对应的reduceReduce阶段:
Reduce阶段:
1.group by:对map端发送过来的数据进行分组并进行计算。 2.select:最后过滤列用于输出结果 3.limit排序后进行结果输出到HDFS文件 FROM … WHERE … SELECT … GROUP BY … HAVING … ORDER BY …
4.1.1 sql 执行顺序


- sql语句 执行顺序 拆分

4.2.Hive update 需要表设置
由于涉及到存储过程改造,需要更新操作,因此需要开启update 特性

hive.support.concurrency true hive.enforce.bucketing true hive.exec.dynamic.partition.mode nonstrict hive.txn.manager org.apache.hadoop.hive.ql.lockmgr.DbTxnManager hive.compactor.initiator.on true hive.compactor.worker.threads 1
Shell 开启:
Update is allowed for ORC file formats only. Also you have to set few properties before performing the update or delete. Client Side set hive.support.concurrency=true; set hive.enforce.bucketing=true; set hive.exec.dynamic.partition.mode=nonstrict; set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; Server Side (Metastore) set hive.compactor.initiator.on=true; set hive.compactor.worker.threads=1; After setting this create the table with required properties
CREATE TABLE test_result
(run_id VARCHAR(100), chnl_txt_map_key INT) clustered by (run_id) into 1 buckets ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ STORED AS orc tblproperties (“transactional”=“true” );
注意!Hive3.1.2 需要配置hive-site.xml 只是创建时指定"transactional"=“true” 是不能执行insert 和update
4.3.Hive脚本中设置变量
由于存储过程中涉及到变量,两种方式,一种采用shell 方式,一种采用 hive 提供的设置变量的方式


4.7批量更新
存储过程改造过程,涉及到批量更新的操作,改造过程中遇到,批量更新的问题,幸运的是hive 2.2 已经支持了批量更新的特性
hive2.2 支持merge into 功能实现和mysql批量update 功能 类似的功能
- hive2.2.0及之后的版本支持使用merge into 语法,使用源表数据批量更新目标表的数据。使用该功能还需做如下配置
1、参数配置
set hive.support.concurrency = true; set hive.enforce.bucketing = true; set hive.exec.dynamic.partition.mode = nonstrict; set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; set hive.compactor.initiator.on = true; set hive.compactor.worker.threads = 1; set hive.auto.convert.join=false; set hive.merge.cardinality.check=false; – 目标表中出现重复匹配时要设置该参数才行
2、建表要求
Hive对使用Update功能的表有特定的语法要求, 语法要求如下: (1)要执行Update的表中, 建表时必须带有buckets(分桶)属性 (2)要执行Update的表中, 需要指定格式,其余格式目前赞不支持, 如:parquet格式, 目前只支持ORCFileformat和AcidOutputFormat (3)要执行Update的表中, 建表时必须指定参数(‘transactional’ = true);

4.71 批量更新语法
MERGE INTO AS T USING <source expression/table> AS S
ON <boolean` `expression1> WHEN MATCHED [AND <booleanexpression2>] THEN UPDATE SET WHEN MATCHED [AND <boolean` `expression3>] THEN DELETE WHEN NOT MATCHED [AND <booleanexpression4>] THEN INSERT VALUES
Example
CREATE DATABASE merge_data; CREATE TABLE merge_data.transactions( ID int, TranValue string, last_update_user string) PARTITIONED BY (tran_date string) CLUSTERED BY (ID) into 5 buckets STORED AS ORC TBLPROPERTIES (‘transactional’=‘true’);
CREATE TABLE merge_data.merge_source(
ID int, TranValue string, tran_date string) STORED AS ORC;
INSERT INTO merge_data.transactions PARTITION (tran_date) VALUES
(1, ‘value_01’, ‘creation’, ‘20170410’), (2, ‘value_02’, ‘creation’, ‘20170410’), (3, ‘value_03’, ‘creation’, ‘20170410’), (4, ‘value_04’, ‘creation’, ‘20170410’), (5, ‘value_05’, ‘creation’, ‘20170413’), (6, ‘value_06’, ‘creation’, ‘20170413’), (7, ‘value_07’, ‘creation’, ‘20170413’), (8, ‘value_08’, ‘creation’, ‘20170413’), (9, ‘value_09’, ‘creation’, ‘20170413’), (10, ‘value_10’,‘creation’, ‘20170413’);
INSERT INTO merge_data.merge_source VALUES
(1, ‘value_01’, ‘20170410’), (4, NULL, ‘20170410’), (7, ‘value_77777’, ‘20170413’), (8, NULL, ‘20170413’), (8, ‘value_08’, ‘20170415’), (11, ‘value_11’, ‘20170415’);
注意执行 merge into 前设置:set hive.auto.convert.join=false; 否则报:ERROR [main] mr.MapredLocalTask: Hive Runtime Error: Map local work failed 注意! update set 语句后面的 字段不用加表别名否则会报错 示例:SET TranValue = S.TranValue
MERGE INTO merge_data.transactions AS T
USING merge_data.merge_source AS S ON T.ID = S.ID and T.tran_date = S.tran_date WHEN MATCHED AND (T.TranValue != S.TranValue AND S.TranValue IS NOT NULL) THEN UPDATE SET TranValue = S.TranValue, last_update_user = ‘merge_update’ WHEN MATCHED AND S.TranValue IS NULL THEN DELETE WHEN NOT MATCHED THEN INSERT VALUES (S.ID, S.TranValue, ‘merge_insert’, S.tran_date);
4.5 函数
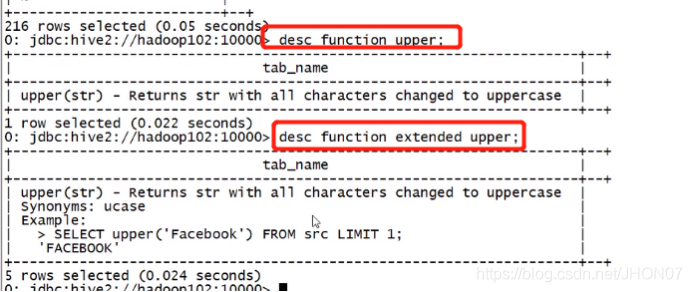
desc function upper;
Desc function extended upper;
4.6.Hive 自定义udf 函数
公司中一般写UDF比较多:utdf ,
参考的网址:


4.6.1 临时函数


4.6.2 永久函数
创建永久函数:
hadoop fs -mkdir /lib
hdfs dfs -put /home/hadoop/jar/add_months-1.0-SNAPSHOT.jar /lib
CREATE FUNCTION user_info.add_month AS “com.hivefunction.AddMonths” USING JAR “hdfs://localhost:9000/lib/add_months-1.0-SNAPSHOT.jar”;
4.7.Hive 优化:
4.7.1.Fetch 抓取
Config.xml配置

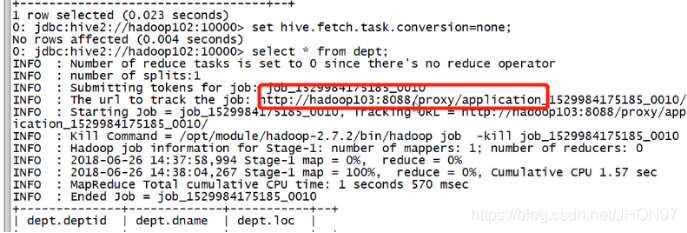
4.7.2.本地模式:
默认是提交到yarn 上进行执行
测试环境,可以设置为本地模式更快;
4.7.3.大表join 小表 mapjoin设置
过滤掉空key

为了防止数据倾斜:可以给null 赋一个随机值,
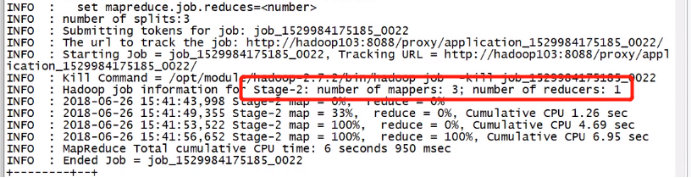
Set mapreduce.job.reduces=5 设置5个reduce 注意!UI 查看reduces 时间,从applicationId -->history—>reducer查看每个reducer 执行从时间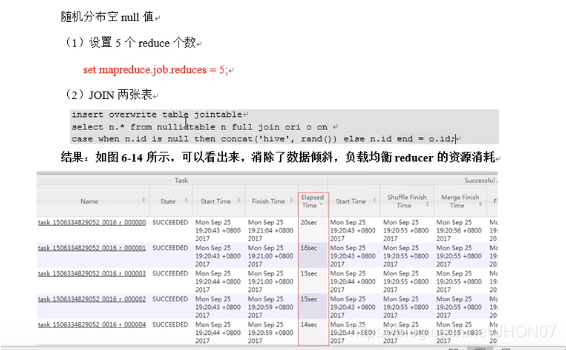
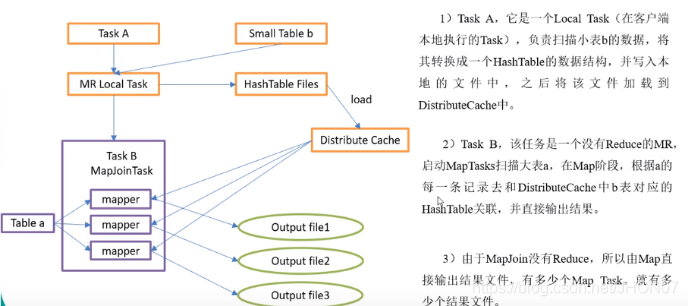
4.7.4.Mapjoin
Set hive.mapjoin.smalltable.filesize=256000000 设置小表的大小,依据机器内存大小设置

4.7.5.Group by 优化
设置map进行聚合:
Combatiner 聚合: hive.map.aggr =true; 注意!添加combatiner组件操作,结果(业务逻辑不会变)不会变时使用 Hive.group by.skewindata=true ;

4.7.6.Count(distinct) 去重统计
Count(disticnt) distinct 是在一个reduce 处理,会出现数据倾斜的情况
Select count(distinct id) from bigtable 会看到 map处理完的数据放在一个reduce 中进行处理;注意!count(id) 最终会放到一个reduce中执行;
优化: 先group by 然后在统计:
Select count(id) from (select id from bigtable group by id) a;
4.7.7.笛卡尔积:

4.7.8.行列过滤
谓词下推:先过滤 通过子查询然后在关联表

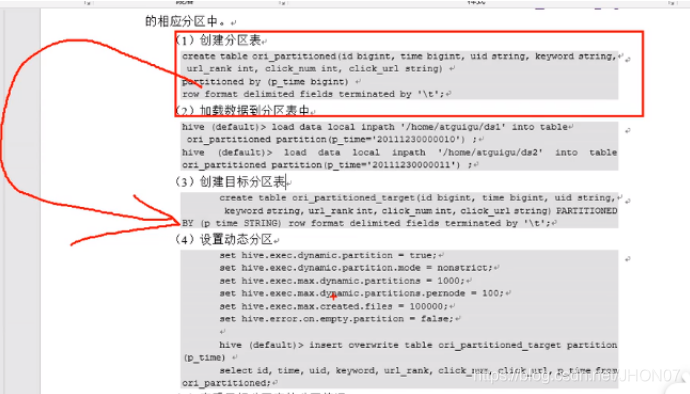
4.7.9.动态分区
其实是依据表中的一个字段作为动态分区的字段
每个Mr默认设置分区是1000

首先是将数据导入到静态分区,然后在导入的动态分区中去:

实例入下图
4.7.10.数据倾斜
Map 数量设置
当小文件过多时,合并小文件 当文件大小一定时,字段就两三个,这样记录上亿条,需要降低 split.maxsize 增加map的数量;注意!看下面的公式;
当小文件过多时,合并小文件
当文件大小一定时,字段就两三个,这样记录上亿条,需要降低 split.maxsize 增加map的数量;注意!看下面的公式;

4.7.10.1.小文件合并:

4.7.10.2.复杂文件增加Map数量
当设置 map,reduce数量是-1时系统才会自动根据设置分片的大小进行动态切片


4.7.10.3.设置reduce的数量

4.7.10.4.并行执行
多个阶段执行 并且没有依赖时打开:(hive中某几个阶段没有依赖)

4.7.10.5.Hive 严格模式
生产环境:肯定是严格模式
严格模式下,一些不允许的操作: 笛卡尔积是不允许的 分区表查询,必须带分区 Order by 时必须带limit

4.7.10.6.Jvm重用
可以在程序中手动设置: set mapreduce.job.jvm.numtasks=10;
或者在xml 文件中配置; 注意!Jvm 重用是针对同一个job中不同task的jvm重用;


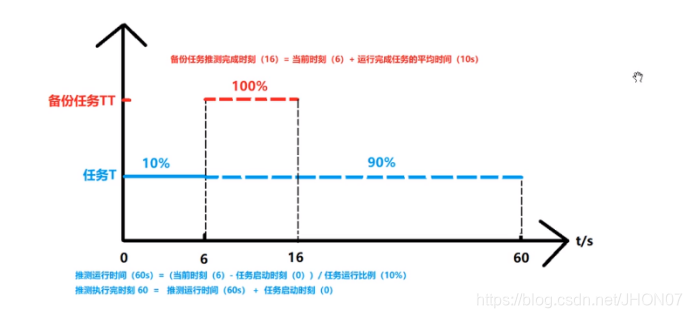
4.7.10.7.推测执行
默认是开启的;


4.7.10.8.压缩见hive格式
4.7.10.9.explain
5.Sqoop语句如下:

hive 与mysql 数据类型映射关系


总结 mysql 中的double 有保留值例如double(10,7) 映射成hive 处理为decimal(10,7) 在数值计算过程中,计算结果和存储过程计算结果没有出入;
6.Hive 高级函数:

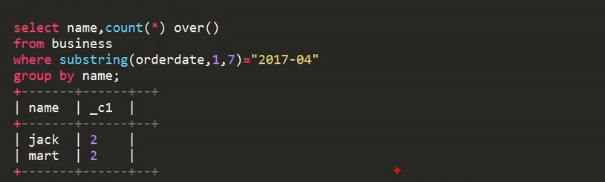
Over 一般跟在聚合函数的后面,指定窗口的大小
Select name,count(*) over() from business where subString(orderdate,1,7)=”2017-04” group by name ;
Group by name 后over() 函数依据的是分组后的两行进行计算;
7 常见的面试题
7.1.Left semi join 和left join 的区别
LEFT SEMI JOIN (左半连接)是 IN/EXISTS 子查询的一种更高效的实现
Left semi join 相当于 in(keyset) 遇到右表重复记录,会跳过,而join是一直遍历,join会出现重复结果;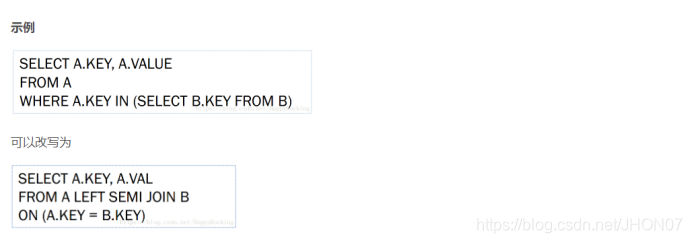


7.2.数据库拉链表
记录一个食物从开始一直到当前状态所有的状态的信息;
适应场景: 数据模型设计中遇到如下问题: 适用拉链表

例如一张流水表: ods_account
Hive 上一张流水记录表 ods_account_his 采用批量增加改变的添加到 ods_account_his
- 拉链表的逻辑设计
接下来通过一个实例来简述一下应该如何设计拉链表
首先,针对于某账户信息表,在2018年1月1日的信息如下表(为了简化设计,这里增加了信息变更时间UPDATE_DATE):
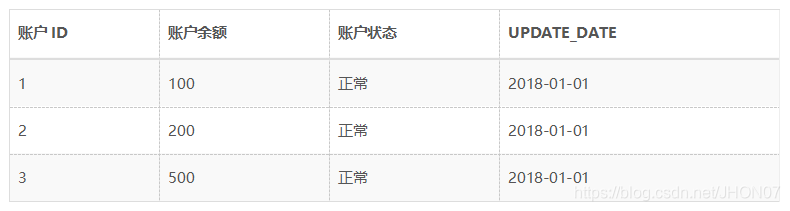
UPDATE_DATE):
由此表我们可以得到以下拉链表,开始时间和结束时间表示数据的生命周期,结束时间9999-99-99表示此条数据为当前时间的数据:
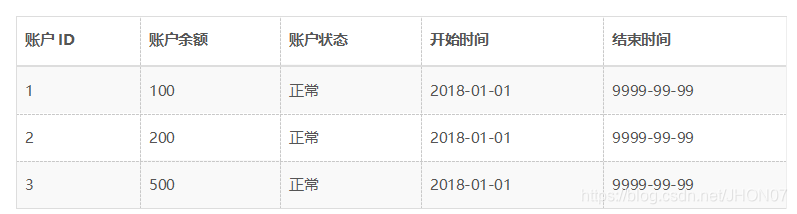
接下来,在2018年1月2日做数据采集时,采集到了UPDATE_DATE为2018-01-02的以下数据:
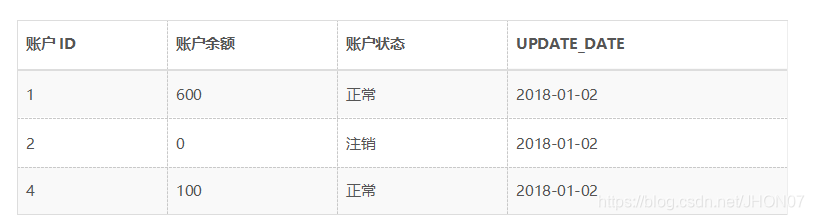
通过两个表的对比可以得出,对于同一个账户ID来说,1号账户的账户余额发生变更变成了600,2号账户的余额发生变更变成了100,则我们可以根据这张表和上面的拉链表关联,得到新的拉链表:
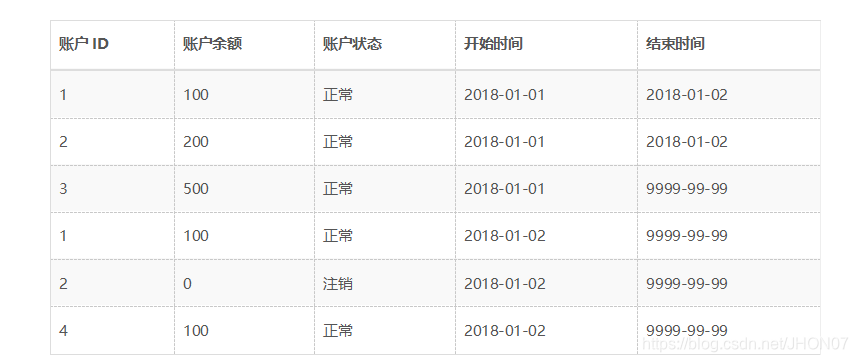
以此类推,我们可以查询到2018年1月1日之后的所有生命周期的数据,例如:
o查询当前所有有效记录: SELECT * FROM ACCOUNT_HIST WHERE END_DATE = ‘9999-99-99’ o查询2018年1月1日的历史快照:SELECT * FROM ACCOUNT_HIST WHERE START_DATE <= ‘2018-01-01’ AND END_DATE >= ‘2018-01-01’
7.3 抽取数据库中存在json数据怎么处理
推荐处理的函数 get_json_object 、 json_tuple、 regexp_replace
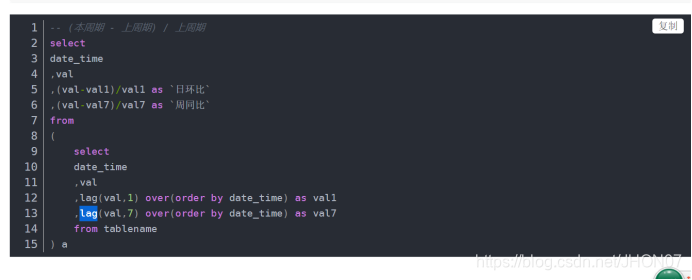
7.4 求日环比和月环比
7.5 数据仓库和数据集市
8. hadoop-yarn 参数调优
例1:
假设一台服务器,内存128G,16个pcore,需要安装DataNode和NodeManager, 具体如何设置参数? 1)装完CentOS,消耗内存1G; 2)系统预留15%-20%(包含第1点),防止全部使用二导致系统夯住或者OOM机制事件, 或者给未来部署其他组件预留空间。此时余下12880%=102G 3)DataNode设定2G,NodeManager设定4G,则剩余102-2-4=96G; 4)明确两点:pcore:vcore=1:2 ,故vcore数量为162=32;单个container占用4个vcore 5)确定 memory和vcore yarn.nodemanager.resource.cpu-vcores --> 32 # 16*2=32 yarn.scheduler.minimum-allocation-vcores --> 1 # 最多有32个container yarn.scheduler.maximum-allocation-vcores --> 4 # 最少有8个container yarn.nodemanager.resource.memory-mb --> 96G # RM能使用的最大内存 yarn.scheduler.minimum-allocation-mb --> 1G # yarn.scheduler.maximum-allocation-mb --> 12G # 极限8个(96/8) 注意:若有spark组件,当spark计算时内存不够大, yarn.scheduler.maximum-allocation-mb势必要调大, 则这种理想化的设置会被打破,以memory为主
转载地址:http://zliu.baihongyu.com/